
내 PC/서버에 직접 설치해 텔레그램·디스코드로 제어하는 셀프호스팅 AI 에이전트 플랫폼입니다.
외부 서버 없이 로컬 환경에서 Claude, GPT 등 LLM을 연결해 나만의 AI 직원을 구성할 수 있습니다.
"API 요금이 매달 부담스럽다", "회사 기밀 데이터를 외부 서버로 보내고 싶지 않다" — 상용 AI를 쓰다 보면 누구나 한 번쯤 이런 고민에 부딪힙니다. 가장 똑똑한 모델을 기본으로 쓰자니 토큰 비용이 폭증하고, 민감한 사내 문서를 AI에 던져주기가 꺼려지는 상황, 해결책이 없을까요?
이번 22편에서는 openclaw ollama 연결을 통해 단돈 1원의 API 요금 없이, 외부 서버로 데이터를 한 바이트도 보내지 않는 100% 프라이빗 로컬 AI 에이전트를 구축하는 방법을 처음부터 끝까지 다룹니다. 적당한 사양의 PC와 이 글 하나면 충분합니다.
지난 편(21편: Models 설정 완전 가이드 — GPT·Claude·Gemini 연결 비교)에서는 상용 모델들의 특성과 가성비 설정 전략을 배웠습니다. 이번 편에서는 그 연장선에서, 클라우드 API 없이 내 컴퓨터 자원만으로 AI를 구동하는 궁극의 방법을 실습합니다.
왜 Ollama인가? — 로컬 모델의 장점과 한계
Ollama는 Llama 3, Mistral, Qwen 등 강력한 오픈소스 AI 모델들을 내 컴퓨터에서 극도로 쉽게 실행할 수 있게 해주는 도구입니다. openclaw 설치 후 Ollama를 연동하면 진정한 의미의 셀프호스팅 AI가 완성됩니다. 선택 전에 장단점을 명확히 파악하는 것이 중요합니다.
장점 — 비용·보안·오프라인
- 완전 무료: 수만 번을 호출해도 요금이 0원입니다. 초기 모델 다운로드 이후 추가 비용이 없습니다.
- 완전한 프라이버시: 대화 내용, 사내 기밀 문서, 개인 데이터가 외부 서버로 전송되지 않습니다. 오프라인 환경에서도 작동합니다.
- 무제한 커스터마이징: 모델을 직접 파인튜닝하거나 특정 도메인에 최적화된 오픈소스 모델로 교체하는 것이 자유롭습니다.
단점 — 성능·하드웨어
- 성능 격차: Claude Sonnet, GPT-4o 같은 최고급 상용 모델에 비해 복잡한 코딩이나 긴 문맥 이해 능력이 떨어질 수 있습니다.
- 하드웨어 요구: 원활한 구동을 위해 GPU(그래픽카드) 또는 16GB 이상의 RAM이 권장됩니다. 사양이 낮으면 응답이 매우 느려질 수 있습니다.
📎 공식 문서 원문 보기 →
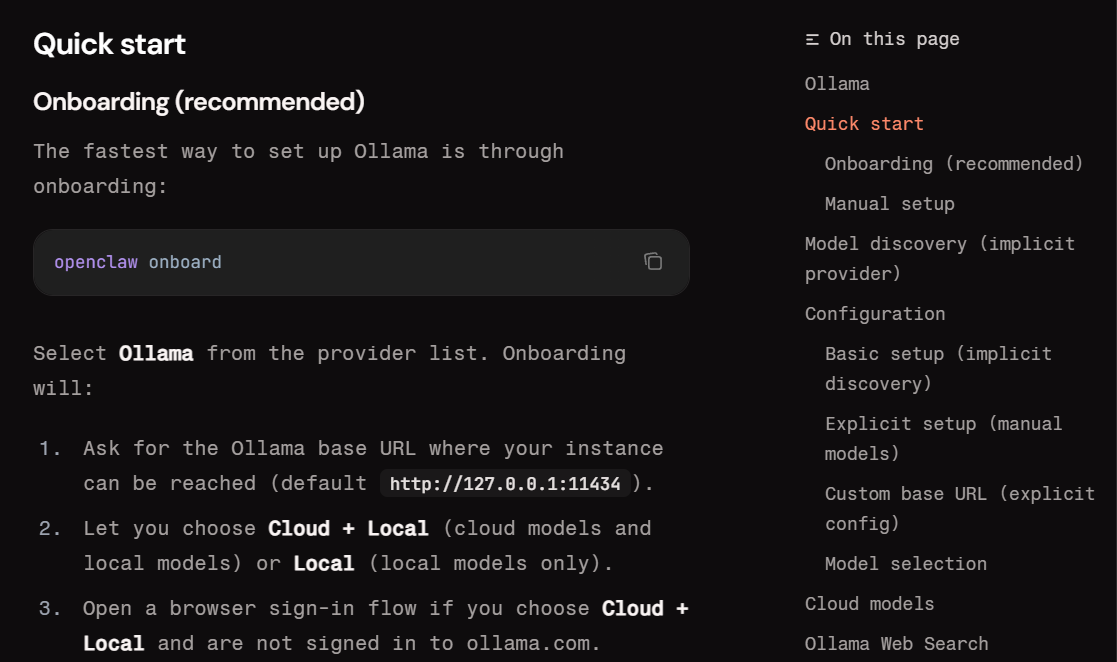
1단계: Ollama 설치 및 로컬 모델 다운로드
먼저 PC(또는 서버)에 Ollama를 설치하고 모델을 다운로드합니다. ollama.com에서 운영체제(macOS·Windows·Linux)에 맞는 설치 파일을 받아 설치한 후 아래 명령어를 실행합니다.
모델 다운로드 및 첫 실행
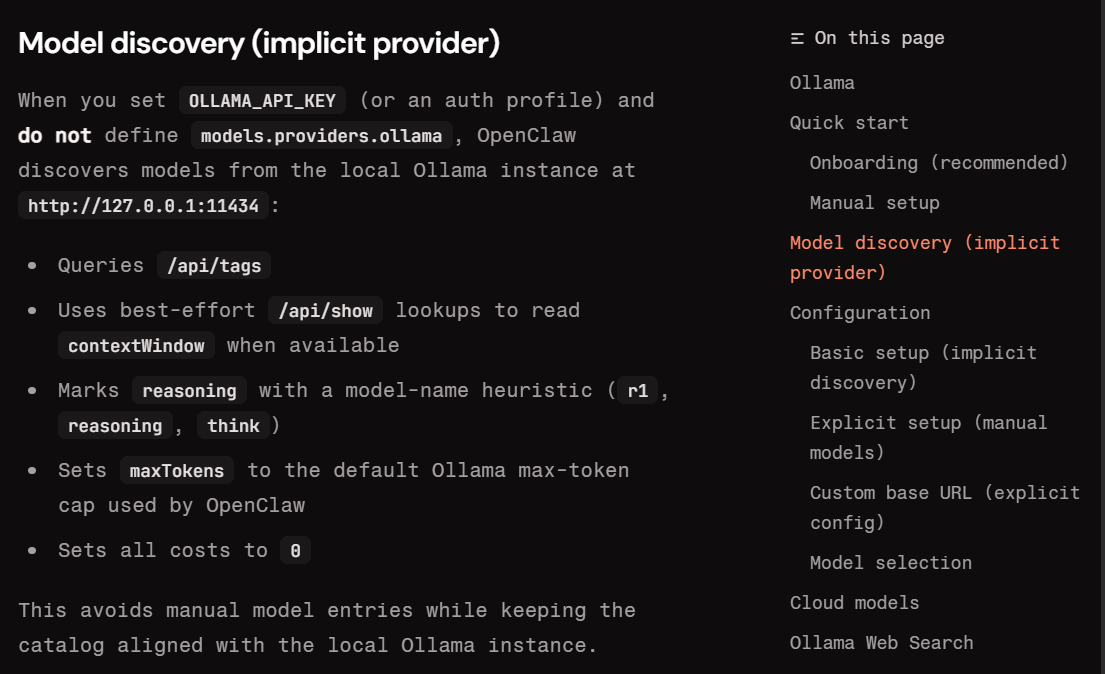
아래 명령어로 가볍고 빠른 llama3.2:3b 모델을 다운로드하고 실행합니다. 모델 크기는 약 2GB이며, 완료 후 대화 프롬프트가 뜨면 성공입니다.
# Llama 3.2 (3B) 모델 다운로드 및 실행
ollama run llama3.2:3b실행에 성공하면 Ollama 서버가 내 PC의 http://localhost:11434 포트에서 백그라운드로 대기 상태에 들어갑니다. OpenClaw는 이 주소로 로컬 모델에 접근합니다.
ollama run qwen2.5:7b 또는 ollama run EEVE-Korean 같은 한국어 최적화 모델을 선택하세요. ollama.com/library에서 전체 모델 목록을 확인할 수 있습니다.2단계: openclaw.json에 Ollama 연동 설정하기
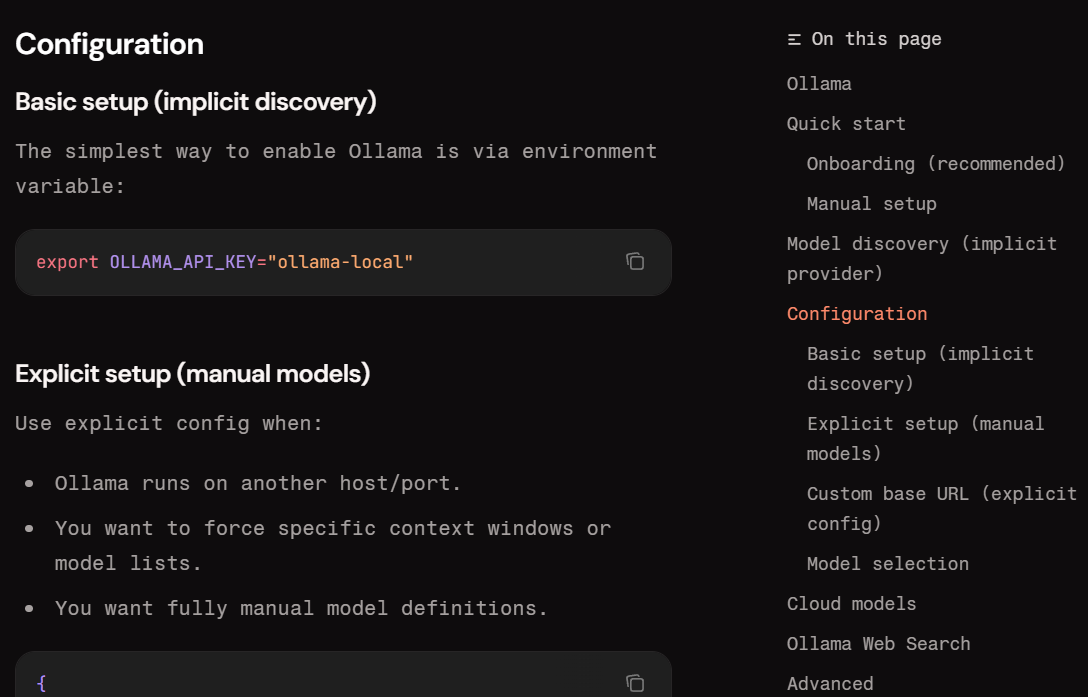
이제 ~/.openclaw/openclaw.json 설정 파일을 수정하여 에이전트의 두뇌를 로컬 모델로 교체합니다. 아래 순서대로 따라 하시면 10분 내에 완료됩니다.
- 설정 파일 열기선호하는 편집기로 OpenClaw 설정 파일을 엽니다.
nano ~/.openclaw/openclaw.json- models.providers 블록에 Ollama 등록
api필드를 반드시"openai-completions"로 설정하는 것이 핵심입니다. 이 규격이 맞아야 OpenClaw와 Ollama가 오류 없이 통신합니다. { "models": { "mode": "merge", "providers": { "ollama": { "baseUrl": "http://localhost:11434", "apiKey": "ollama-local", "api": "openai-completions", "models": [ { "id": "ollama/llama3.2:3b", "name": "llama3.2:3b", "reasoning": false, "input": ["text"], "cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 }, "contextWindow": 130000, "maxTokens": 8000 } ] } } }, "agents": { "defaults": { "model": { "primary": "ollama/llama3.2:3b" } } } }- 게이트웨이 재시작설정 파일을 저장한 후 게이트웨이를 재시작해 변경사항을 반영합니다.
openclaw gateway restart- 동작 확인에이전트에게 "지금 어떤 모델을 쓰고 있어?" 라고 질문해서 로컬 모델이 정상 응답하는지 확인합니다.
cost 필드를 모두 0으로 설정해 두면 OpenClaw 대시보드에서 이 모델 호출은 비용 0원으로 집계됩니다. 나중에 상용 모델과 비용 비교 분석 시 유용합니다.로컬 모델 운영 필수 주의사항 — 보안·스킬 제한
설정 완료 후 바로 쓸 수 있지만, 장기 안정 운영을 위해 반드시 챙겨야 할 주의사항이 있습니다. 로컬 소형 모델의 한계를 이해하고 그에 맞게 환경을 조정해야 시스템이 흔들리지 않습니다.
스킬(Skills)은 필수 2~5개만 활성화
7B~13B 수준의 소형 모델은 컨텍스트 윈도우(기억력)가 상용 모델보다 좁습니다. browser·exec 같이 복잡한 시스템 프롬프트를 요구하는 스킬을 여러 개 켜두면 정작 사용자와 대화할 공간이 부족해져 성능이 급격히 저하됩니다. 꼭 필요한 스킬(calendar, web_search 등)만 2~5개 활성화하는 것이 원칙입니다.
exec(시스템 명령 실행) 권한을 꼭 사용해야 한다면 반드시 "approval": true를 설정하고, 실행 가능한 명령 범위를 최소화하세요.// 로컬 모델 환경 권장 보안 설정
"tools": {
"exec": {
"enabled": true,
"approval": true // 실행 전 반드시 사람이 승인
}
}api: "openai-completions" 규격으로 openclaw.json 등록 → 게이트웨이 재시작 3단계면 완전 무료 로컬 AI가 완성됩니다. 스킬은 최소화하고 exec 권한은 반드시 승인 모드로 운영하세요.
실전 팁과 주의사항
- 처음엔 3B 모델로 시작: llama3.2:3b는 약 2GB로 가볍고 빠릅니다. 성능이 부족하다면 7b → 13b 순으로 단계적으로 업그레이드하세요.
- 한국어 성능이 부족하면 모델을 교체: Qwen 2.5나 한국어 파인튜닝 모델(
EEVE-Korean등)로 바꾸면 훨씬 자연스러운 한국어 대화가 가능합니다. - Docker 환경이라면 baseUrl 주의: OpenClaw가 Docker 컨테이너 안에서 실행 중이라면
localhost대신host.docker.internal을 사용해야 Ollama 서버에 접근할 수 있습니다. - 상용 모델과 병행 운영 가능: 복잡한 작업에는 상용 모델(Claude Sonnet), 단순 반복·프라이빗 데이터 처리에는 로컬 Ollama를 쓰는 하이브리드 구성이 가장 실용적입니다.
자주 묻는 질문 (FAQ)
- Ollama를 연결하려는데 "Connection refused" 에러가 납니다.
- 설정 파일의
baseUrl값과 Ollama가 실제 실행 중인 주소가 다를 때 발생합니다. Ollama는 기본적으로http://localhost:11434를 사용합니다. Docker 컨테이너 안에서 OpenClaw가 실행 중이라면localhost대신host.docker.internal을 입력하세요. - 로컬 모델이 한국어를 잘 못 알아들어요.
- Llama 3·Mistral 같은 기본 모델은 영어 중심입니다. ollama.com/library에서
qwen2.5또는 한국어 파인튜닝 모델을 검색해ollama run 모델명으로 다운로드한 뒤, openclaw.json의id값을 해당 모델명으로 변경하면 훨씬 자연스러운 한국어 응답을 받을 수 있습니다. - 로컬 모델에서도 파일 읽기, 웹 검색 같은 Tools 기능이 작동하나요?
- 네, 작동합니다.
api: "openai-completions"규격만 올바르게 설정하면 로컬 모델도 OpenClaw의 도구(Tools) 목록을 이해하고 활용할 수 있습니다. 다만 모델의 파라미터 크기(지능)에 따라 도구를 얼마나 능숙하게 사용하는지에는 차이가 납니다. - 노트북 사양이 낮아 로컬 모델이 너무 느립니다. 대안이 있나요?
- Haimaker, OpenRouter 같은 클라우드 중개 서비스를 통해 Llama 3.3, Qwen 3 등 오픈소스 모델 API를 매우 저렴하게(때로는 무료 티어로) 호출할 수 있습니다. 내 PC 자원을 쓰지 않으면서도 상용 모델 대비 파격적으로 저렴하게 셀프호스팅 AI를 운영할 수 있는 실용적인 대안입니다.
이 글이 도움이 됐다면 댓글로 여러분의 경험을 알려주세요! 🙌
openclaw ollama 연결에서 막히는 부분은 댓글에 남겨주세요 — 직접 답변드립니다.
📬 새 편 알림 받기 → AI 활용 가이드 구독
'OpenClaw' 카테고리의 다른 글
| 오픈클로 완전 가이드 24편 openclaw 원격 접속 설정 — Tailscale·SSH 터널로 어디서나 안전한 AI 에이전트 만들기 (1) | 2026.04.08 |
|---|---|
| 오픈클로 완전 가이드 23편 Gateway 설정 완전 가이드 — 포트·토큰·데몬 상시 실행 (0) | 2026.04.08 |
| 오픈클로 완전 가이드 21편 Models 설정 완전 가이드 — GPT·Claude·Gemini 연결 비교 (0) | 2026.04.07 |
| 오픈클로 가이드 20편 openclaw MCP 연동 — 외부 데이터 연결 완전 가이드 (0) | 2026.04.04 |
| 오픈클로 완전 가이드 19편 커스텀 Tool 만들기 — Python 스크립트를 AI 도구로 등록하는 법 (1) | 2026.04.04 |



댓글